Getting Started
First, you need to install the right tools.
pip install beautifulsoup4
pip install requests
pip install lxmlThese are the ones we will use for the scraping. Create a new python file and import them at the top of your file.
from bs4 import BeautifulSoup
import requestsFetch with Requests
The Requests library will be used to fetch the pages. To make a GET request, you simply use the GET method.
result = requests.get("www.google.com")You can get a lot of information from the request.
# Get the Status Code
result.status_code
# Get the Headers
result.headersTo be able to scrape your page, you need to use the Beautiful Soup library. You need to save the response content to turn it into a soup object.
# Save the Content
content = result.content
# Create Soup
soup = BeautifulSoup(content, features="lxml")You can see the HTML in a readable format with the prettify method.
print(soup.prettify())Scrape with Beautiful Soup
Now to the actual scraping. Getting the data from the HTML code.
Using CSS Selector
The easiest way is probably to use the CSS selector, which can be copied within Chrome.
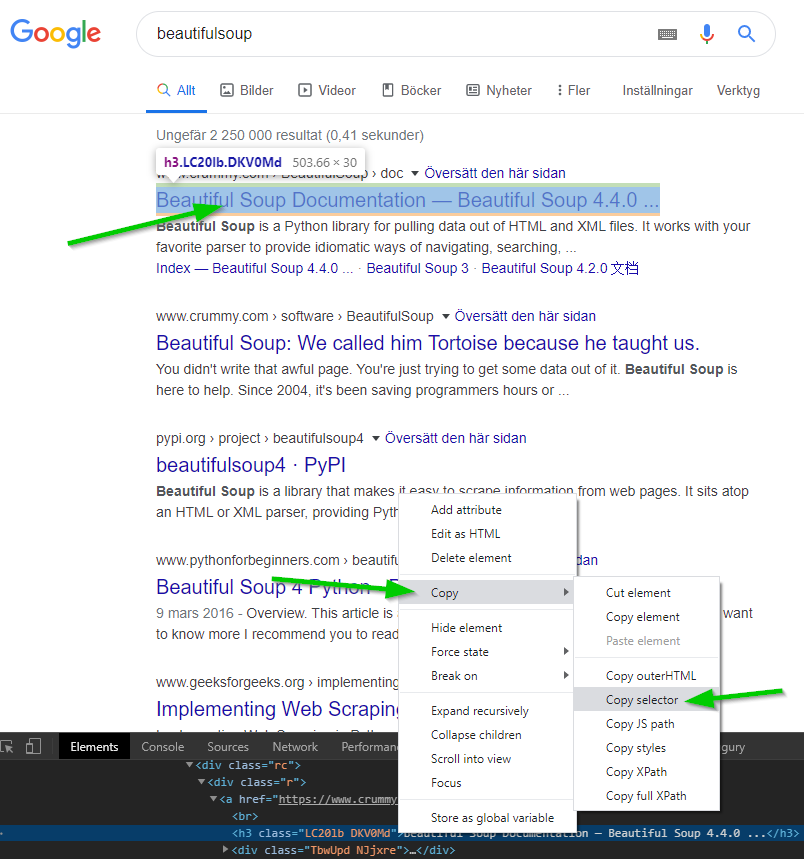
Here, I have selected the first Google result. Inspected the HTML. Right clicked the element, selected copy and choose the Copy selector alternative.
samples = soup.select("div > div:nth-child(4) > div:nth-child(4)")The select element will, however, return an array. If you only want one object, you can use the select_one method instead.
Using Tags
You can also scrape by tags (a, h1, p, div) with the following syntax.
# All a Elements
samples = soup.select("a")
# Chain Tags in the Following Order: (HTML -> Head -> A)
samples = soup.select("html head a")
# Chain Tags in the Exact Following Order: (HTML -> Head -> A)
samples = soup.select("html > head > a")It is also possible to use the id or class attribute to scrape the HTML.
sample_id = soup.select("#id")
sample_class = soup.select(".class")Using Find_all
Another method you can use is find_all. It will basically return all elements that match.
# Return All Elements with an a Tag
samples = soup.find_all("a")
# Return All Elements with a Specific ID
samples = soup.find_all(id="specific_id")
# Return All Elements with a "A" Tag with a Specific CSS Class
samples = soup.find_all("a", "specific_css_class")
# Same as Above, More Specific
samples = soup.find_all("a", class_="specific_css_class")
# Search for Any Attribute Within an a Tag
samples = soup.find_all("a", attrs={"class": "specific_css_class"})You can also use the find method, which will return a single element instead of an array.
Get the Values
The most important part of scarping is getting the actual values (or text) from the element.
<h3 class="LC20lb DKV0Md" href="https://someurl.com/">Beautiful Soup</h3>Get the inner text (the actual text printed on the page) with this method.
sample = element.get_text()If you want to get a specific attribute of an element, like the href, use this syntax:
sample = element.get("href")